查找表是由同一类型的数据元素构成的集合,元素之间存在着松散关系
常用操作包括:
- 查询某个特定的数据元素是否在查找表中
- 检索某个特定的数据元素的各种树型
- 在查找表中插入一个元素
- 在查找表中删除一个元素
查找表的分类:
- 静态查找表:只允许查询和检索操作的查找表
- 动态查找表:除了查询和检索外,还允许插入和删除的查找表
数据元素中某个数据项的值,用来标识一个数据元素,叫做关键字,若它可以识别唯一的一个记录,则叫做主关键字,若可识别若干记录,则称为次关键字,查找表的查询和检索通常是根据关键字进行的
根据给定的值,在查找表中确定一个关键字等于给定值的数据元素或记录,若存在这个数据元素,则查找成功,给出元素信息或指示它的位置,否则就是查找不成功,给出空记录或空指针
查找的方法的选择和设计要看查找表的存储方式,为了提高查找的效率, 需要在查找表中的元素之间人为地附加某种确定的关系,即: 用另外一种结构来表示查找表
可以通过以下方法评价查找方法:
- 平均查找长度ASL(Average Search Length):为确定记录在表中的位置,需要与给定值进行比较的次数的期望值叫查找算法的平均查找长度
- 使用存储空间多少
1 静态查找表
1.1 顺序表查找
如查找表组织成线性表,存储结构为数组,则称为顺序表
#define MAX 100
typedef struct{
KeyType key;
}ElemType; // KeyType是关键字的类型
typedef struct{
ElemType elemp[MAX];
int length;
}SqList;
它的查找很简单,直接简单的枚举就行
int search(SqList L,KeyType x){
int i;
for(i = 0;i < L.length;i++){
if(L.elem[i].key == x) // 匹配到了
return i+1; // 第i+1个数据元素
}
return 0; // 没找到
}
可以用哨兵优化一下:设置哨兵项,查找表组织成线性表, 线性表的数据元素从下标为1的数组元素开始存放,下标为0的数组元素作为哨兵项,查找x,首先将x放在下标为0的数组元素(哨兵),从表尾开始比较。若在哨兵处相等,说明没找到,否则找到
int srearch(SqList L,KeyType x){
int k = L.length;
L.elem[0].key = x;// 设置哨兵
while(x!=L.elem[k].key)
k--;
return k;
}
// 返回0就是没找到(找到了哨兵)
查找成功的ASL是$\frac{n+1}{2}$,查找一次的ASL是$\frac{3(n+1)}{4}$
1.2 二分查找
查找表组织成有序的线性表(递增递减均可),采用顺序存储结构,可以通过一次比较,将查找范围缩小一半,时间复杂度是$O(\log n)$
二分查找一般用两个指针存储搜索范围的左边边界和右边边界
int binarySearch(SqList L,KeyType x){
int low = 0,high = L.length - 1, m;
// low是左边界,high是右边界,m是中间
while(low<=high){
m = (low+high) / 2;
if(L.elem[m].key == x) return m + 1;
if(L.elem[m].key > x) high = m + 1;
else low = m + 1;
}
return 0; // 没找到
}
查找成功时的平均查找长度$ASL=\log(n+1)-1$,查找失败最坏情况下是$\lfloor \log_{2}n \rfloor + 1$
1.3 索引顺序表
线性表分成若干块,每一块中的键值存储顺序是任意的, 块与块之间按键值排序,即后一块中的所有记录的关键字的值均大于前一块中最大键值
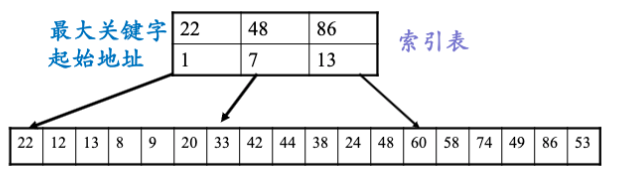
如果要查找值为k的数据元素:
- 首先对索引表采用二分查找或顺序查找方法查找,以确定待查记录所在的块
- 在线性表查找k,若其在线性表中存在,且位于第i块,那么一定有:$第i-1块的最大键值<k\leq第i块的最大键值$
- 然后在相应的块中进行顺序查找
表长为n的线性表 ,整个表分为b块,前$b-1$块中的记录数为$s=\left\lceil \frac{n}{b} \right\rceil$,第b块中的记录数小于或等于s
$$
ASL=\frac{b+1}{2} + \frac{s+1}{2}
$$
当$s=\sqrt{ n }$,ASL最小,为$\sqrt{ n } + 1$
2 动态查找表
2.1 二叉排序树和平衡二叉树
2.1.1 二叉排序树
二叉排序树要么是一颗空树,或者是具有以下特性的二叉树:
- 若它的左子树不空,则左子树上所有结点的值均小于根结点的值
- 若它的右子树不空,则右子树上所有结点的值均大于根结点的值
- 它的左、右子树也都分别是二叉排序树
二叉排序树的中序遍历结果递增有序,即对二叉排序树进行中序遍历,便可得到一个按关键字有序的序列,因此,一个无序序列,可通过构建一棵二叉排序树而成为有序序列
// 二叉链表存储二叉排序树
typedef struct Node{
int key; // 数据元素关键字
...; // 其他数据项
struct Node *lc , *rc; // 左子树右子树
}BiNode,*BiTree;
2.1.1.1 二叉排序树的检索
在二叉排序树中查找是否存在值为x的结点,过程为:
- 若二叉排序树为空,查找失败
- 否则,将x与二叉排序树的根结点关键字值比较,若相等,查找成功,结束,否则
- 若x小于根结点关键字,在左子树上继续进行,转1
- 若x大于根结点关键字,在右子树上继续进行,转1
BiTree Search(BiNode *t,int x){
BiTree p;
p = t;
while(p != NULL){
if(x == p->key)
return p;
if(x < p->key)
p = p->lc; // 左子树继续进行
else
p = p->rc; // 右子树继续进行
}
return p;
}
2.1.1.2 二叉排序树的插入
向二叉排序树中插入x,步骤是:
- 先要在二叉排序树中进行查找,若查找成功, 按二叉排序树定义,待插入数据已存在,不用插入;查找不成功时,则插入它
- 新插入结点是作为叶子结点添加上去的
int Insert(BiTree &t,int x){
BiTree q , p , s;
q = NULL;p=t;// p是正在查看的结点,初始从根节点开始,q是p的双亲结点
// 查找
while(p != NULL){
if(x == p->key)
return 0; // 已经存在,直接返回不插入
q = p;
if(x < p->key) p = p->lc;
else p = p->rc;
}
// 插入
s = (BiTree)malloc(sizeof(BiNode)); //申请结点空间
s->key = x;s->lc=NULL;s->rc=NULL; // 存放x,叶节点
if(q == NULL)
t = s // 如果原来的树是空树,则插入结点为根节点
else if (x < q->key) q->lc =s;
else q->rc = s;
return 1;
}
2.1.1.3 二叉排序树的删除
分为几种情况:
- 被删结点p为叶结点,由于删去叶结点后不影响整棵树的特性,所以只需将被删结点的双亲结点相应指针域改为空指针
- 若被删结点p只有右子树或只有左子树:用左子树或右子树替换被删结点
- 若被删结点p既有左子树又有右子树 ,可按中序遍历保持有序进行调整
- p的左子树pl上的最大值Smax替换p,再删Smax,或
- p的右子树pr上的最小值Smin替换p,再删Smin
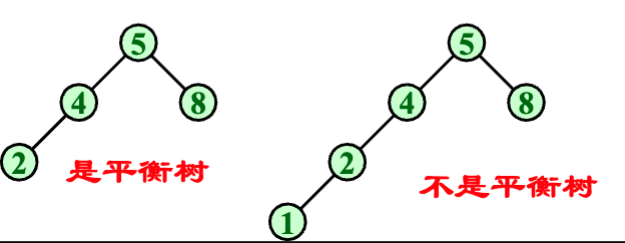
2.2 平衡二叉树
我们希望建的二叉排序树都是平衡二叉树
以下研究的平衡二叉树为平衡二叉排序树
平衡二叉树是空树,或者满足以下性质:
- 左右子树都是平衡二叉树
- 左右子树高度之差的绝对值不超过1
即树中的每个结点的左右子树的高度之差的绝对值不大于一
构造平衡二叉树的方法是在插入过程中采用平衡旋转技术
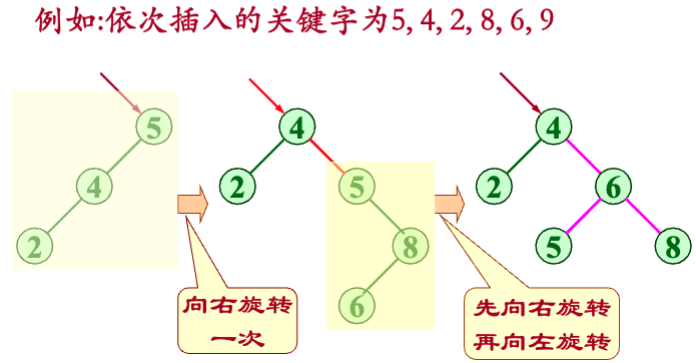
平衡旋转可以归纳为四类:
- LL平衡旋转-单向右旋
- RR平衡旋转-单向左旋
- LR平衡旋转-先左旋再右旋
- RL平衡旋转-先右旋再左旋
2.3 B-树和B+树
暂时略
3 哈希表
哈希表的主要特点是
- 数据元素在表中存放位置和其关键字之间存在一种确定的关系,即预先知道所查关键字在表中的存放位置
- 不进行关键字的比较,直接根据关键字的值确定存储位置,到相应位置上查找
- 确定关键字的值和存储位置的对应关系的函数$h$,称为哈希函数
例:为每年招收的 1000 名新生建立一张查找表,其关键字为学号,其值的范围为xx000–xx999 (前两位为年份)。以下标为000–999 的顺序表表示:根据学号的后3位决定其存放位置,即存放位置为学号的后3位,这个就是哈希函数
例:关键字序列:3,15,22,24,表长=5
地址计算公式(哈希函数):h(k)=k%5
根据设定的哈希函数$h(key)$和所选中的处理冲突的方法,将一组关键字映象到一个有限的、地址连续的地址集 (区间) 上,并以关键字在地址集中的“象”作为相应记录在表中的存储位置,如此构造所得的找表称之为哈希表
3.1 哈希函数
哈希函数是一个映象,即将关键字的集合映射到某个地址集合上,它的设置很灵活,只要这个地址集合的大小不超出允许范围即可
由于哈希函数是一个压缩映象,因此,在一般情况下,很容易产生冲突现象,即
$$
key_{1} \neq key_{2} ,h(key_{1}) =h(key_{2})
$$
发生冲突的两个数据$key_{1},key_{2}$称为“同义词”
实际应用中不保证总能找到一个不产生冲突的哈希函数,一般情况下,只能选择恰当的哈希函数,使冲突尽可能少地产生
因为冲突几乎无法避免,所以在构造这种特殊的查找表时,除了需要选择一个尽可能少产生冲突的哈希函数之外,还需要找到一种处理冲突的方法
3.1.1 构造哈希函数的方法
3.1.1.1 直接定址法
直接用关键字作为哈希函数的线性函数,即
$$
h(key) = key
$$
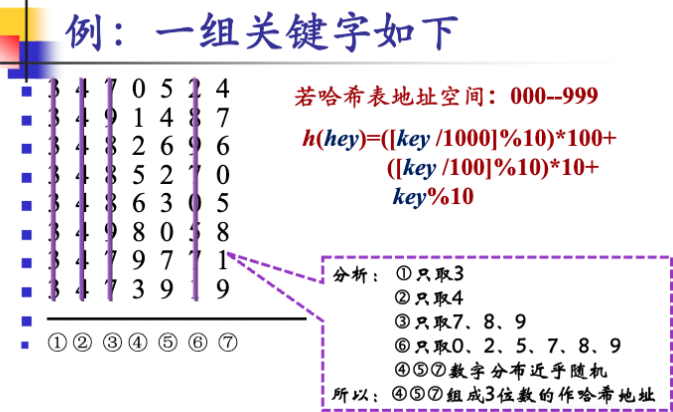
3.1.1.2 数字分析法
假设关键字集合中的每个关键字都是由s位数 字组成$(u_{1},u_{2},\dots,u_{s})$,分析关键字集中的全体,并从中提取分布均匀的若干位或它们的组合作为地址
3.1.1.3 平方取中法
以关键字的平方值的中间几位作为存储地址,因为中间几位能受到整个关键字中各位的影响
3.1.1.4 折叠法
将关键字(自左到右,自右到左)分成位数相等的几部分,最后一部分位数可以短些,然后将这几部分叠加求和作为哈希地址
有两种叠加方法:
- 移位法:将各部分的最后一位对齐相加
- 间界叠加法 :从一端向另一端沿各部分分界来回折叠后,最后一位对齐相加

3.1.1.5 除留余数法
$$
h(key) = key\%p
$$
$p\leq m(m是哈希表表长)$,p为不大于m的素数或是不含20以下的质因子的数
3.1.1.6 随机数法
$$
h(key)=Random(key)
$$
3.1.2 构造选取的方法
选取何种构造函数取决于建表的关键字集合的情况,总的原则是使产生冲突的可能性降到尽可能的小
考虑因素包括:
- 计算哈希函数的时间
- 关键字的长度
- 哈希表的大小
- 关键字的分布
- 记录的查找频率
3.2 冲突处理
处理冲突就是为产生冲突的地址寻找下一个哈希地址
3.2.1 开放定址法
在地址$h(key)$产生冲突,为解决冲突,设定一个地址探测序列$h_{1},h_{2},\dots,h_{k},1\leq k\leq m-1$按照这个探测序列顺序为发生冲突的数据key寻找存放位置,其中$h_{i}=(h(key)+d_{i})\%m,i=1,2,\dots,k$
$d_{i}$称为增量,有三种取法
- 线性探测再散列:$d_{i}=i$
- 平方探测再散列:$d_{i}=1^{2},-1^{2},2^{2},-2^{2},\dots$
- 随机探测再散列:$d_{i}$是一组伪随机序列
增量的说法:
- 产生的$h_{i}$均不相同,且所产生$m-1$个$h_{i}$值能覆盖哈希表中所有地址
- 平方探测时的表长m必为形如$4j+3$的素数( 如: 7, 11, 19, 23, … 等)
- 随机探测时的m和$d_{i}$没有公因子
3.2.2 再哈希法
再哈希一遍
3.2.3 链地址法
冲突之后冲突元素用链表存起来
3.2.4 建立一个公共溢出区
把发生冲突的数据元素顺序存放在一个公共的溢出区
3.3 哈希表的查找
查找和建表过程一致,按照建表一样的步骤计算出内存地址
一般认为哈希表的ASL是处理冲突方法和装载因子的函数,用哈希表构造查找表时,可以选择一个适当的装填因子 α ,使得平均查找长度限定在某个范围内
3.4 哈希表的删除
- 开放定址法 :保证删除后查找表的操作正常进行
- 链地址法:直接删除
- 再哈希法:保证删除后查找表的操作正常进行
- 建立一个公共溢出区:保证删除后查找表的操作
All the best
Enjoy every single day
yahoo,im go
Wish you happiness
Hahahaha You are so good
Good a blog toper
Im 4466,yahoo